Blog Post #2
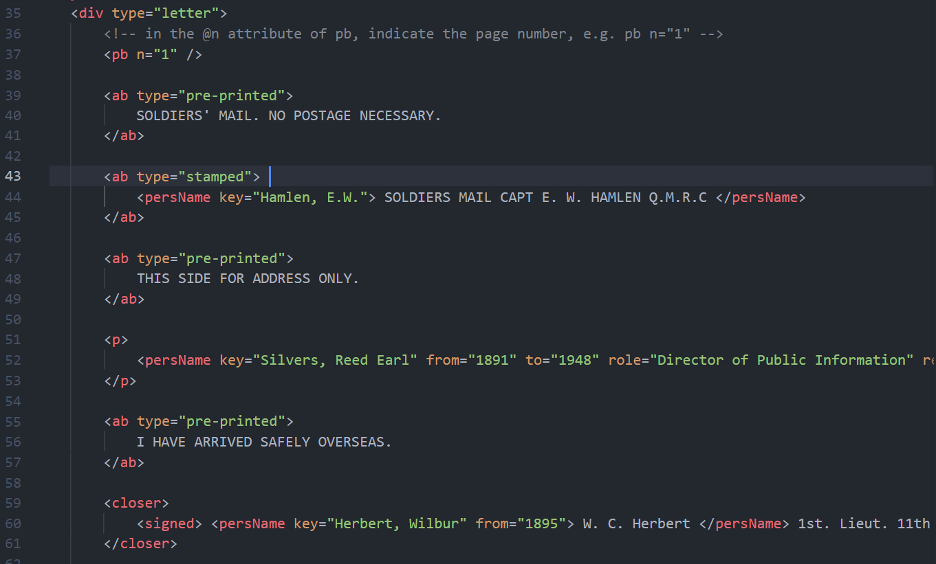
During this TEI-XML lab, I learned a good deal about a programming language that I had never even heard of prior. The aim of this method of TEI close reading and encoding using XML was to both teach us the fundamentals of XML encoding and how it is useful for archiving old hand-written or printed letters and documents. Throughout the lab, I noticed various patterns between the syntax when encoding, most obvious being the syntax of XML, which is standardized in a way that has both closing and opening portions of elements, which makes it very organized and easy to parse through as an encoder. As for the people and places mentioned in the letters, I found that sites like ancestry.com and findagrave.com are very useful in determining some of the information that some XML elements require. While this was a little tedious, in my opinion the hardest part was trying to learn the specific TEI Transcription format itself, learning which parts of my letter correspond to what keys or elements, etc. As seen in the screenshot below, I had to learn about the ab element, which wasn’t present on the github page, and the pre-printed and stamped keys that went along with it. Once I got most of it down, however, I did find the process of searching for these people and writing it in XML interesting, maybe in large part due to the fact that I chose a very short letter, so I could focus more on the syntax rather than simply typing. I realize that this entire lab does indeed connect to some of the previous readings, particularly the ones talking about skewed data and algorithms, and how they can be misused or biased depending on who is in charge. In this lab, we learned how XML transcription encoding standardizes a lot of this, making the bias a lot less prominent.